Counting points on elliptic curves
An important aspect in the study of elliptic curves is devising effective ways of counting points on the curve. There have been several approaches to do so, and the algorithms devised have proved to be useful tools in the study of various fields such as number theory, and more recently in cryptography and Digital Signature Authentication (See elliptic curve cryptography and elliptic curve DSA). While in number theory they have important consequences in the solving of Diophantine equations, with respect to cryptography, they enable us to make effective use of the difficulty of the discrete logarithm problem (DLP) for the group 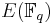 , of elliptic curves over a finite field
, of elliptic curves over a finite field 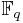 , where q = pk and p is a prime. The DLP, as it has come to be known, is a widely used approach to Public key cryptography, and the difficulty in solving this problem determines the level of security of the cryptosystem. This article covers algorithms to count points on elliptic curves over fields of large characteristic, in particular p > 3. For curves over fields of small characteristic more efficient algorithms based on p-adic methods exist.
, where q = pk and p is a prime. The DLP, as it has come to be known, is a widely used approach to Public key cryptography, and the difficulty in solving this problem determines the level of security of the cryptosystem. This article covers algorithms to count points on elliptic curves over fields of large characteristic, in particular p > 3. For curves over fields of small characteristic more efficient algorithms based on p-adic methods exist.
Contents |
Approaches to counting points on elliptic curves
There are several approaches to the problem. Beginning with the naive approach, we trace the developments up to Schoof's definitive work on the subject, while also listing the improvements to Schoof's algorithm made by Elkies (1990) and Atkin (1992).
Several algorithms make use of the fact that groups of the form are subject to an important theorem due to Hasse, that bounds the number of points to be considered.
Hasse's theorem Let E be an elliptic curve over the finite field . Then the order of satisfies
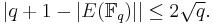
Naive approach
The naive approach to counting points, which is the least sophisticated, involves running through all the elements of the field and testing which ones satisfy the Weierstrass form of the elliptic curve
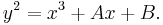
Example
Let 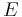 be the curve
be the curve 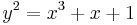 over
over 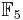 . To count points on , we make a list of the possible values of
. To count points on , we make a list of the possible values of  , then of
, then of 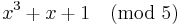 , then of the square roots
, then of the square roots 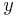 of . This yields the points on .
of . This yields the points on .
|
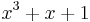 |
|
Points |
|---|---|---|---|
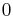 |
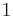 |
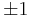 |
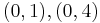 |
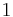 |
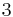 |
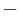 |
|
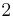 |
|
|
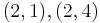 |
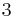 |
|
|
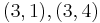 |
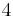 |
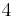 |
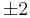 |
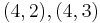 |
Therefore, 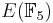 has order 9: the 8 points listed before and the point at infinity.
has order 9: the 8 points listed before and the point at infinity.
This algorithm requires running time 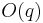 , because all the values of
, because all the values of 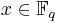 must be considered.
must be considered.
Baby-step giant-step
An improvement in running time is obtained using a different approach: we pick an element 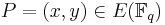 by selecting random values of until
by selecting random values of until 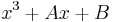 is a square in and then computing the square root of this value in order to get . Hasse's theorem tells us that
is a square in and then computing the square root of this value in order to get . Hasse's theorem tells us that 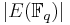 lies in the interval
lies in the interval 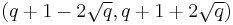 . Thus, by Lagrange's theorem, finding a unique
. Thus, by Lagrange's theorem, finding a unique 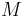 lying in this interval and satisfying
lying in this interval and satisfying 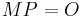 , results in finding the cardinality of . The algorithm fails if there exist two integers and
, results in finding the cardinality of . The algorithm fails if there exist two integers and 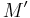 in the interval such that
in the interval such that 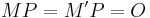 . In such a case it usually suffices to repeat the algorithm with another randomly chosen point in .
. In such a case it usually suffices to repeat the algorithm with another randomly chosen point in .
Trying all values of in order to find the one that satisfies takes around 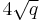 steps.
steps.
However, by applying the baby-step giant-step algorithm to , we are able to speed this up to around ![4 \sqrt[4]{q}](/2012-wikipedia_en_all_nopic_01_2012/I/7bd3c4f1851217aaed04cf5289ec9f68.png) steps. The algorithm is as follows.
steps. The algorithm is as follows.
The algorithm
1. chooseinteger,
2. FOR{
to
4. ENDFOR 5.
6.
7. REPEAT compute the points
8. UNTIL
:
\\the
\\note
be the distinct prime factors of
DO 12. IF
13. THEN
14. ELSE
15. ENDIF 16. ENDWHILE 17.
\\note
18. WHILE
divides more than one integer
in
Notes to the algorithm
- In line 8. we assume the existence of a match. Indeed, the following lemma assures that such a match exists.
Letbe an integer with
. There exist integers
and
with

- Computing
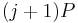 once
once 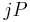 has been computed can be done by adding to instead of computing the complete scalar multiplication anew. The complete computation thus requires additions.
has been computed can be done by adding to instead of computing the complete scalar multiplication anew. The complete computation thus requires additions. 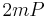 can be obtained with one doubling from
can be obtained with one doubling from 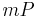 . The computation of
. The computation of 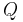 requires
requires 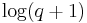 doublings and
doublings and 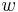 additions, where is the number of nonzero digits in the binary representation of
additions, where is the number of nonzero digits in the binary representation of 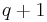 ; note that knowledge of the and allows us to reduce the number of doublings. Finally, to get from to
; note that knowledge of the and allows us to reduce the number of doublings. Finally, to get from to 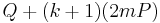 , simply add rather than recomputing everything.
, simply add rather than recomputing everything.
- We are assuming that we can factor . If not, we can at least find all the small prime factors
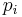 and check that
and check that 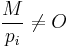 for these. Then will be a good candidate for the order of .
for these. Then will be a good candidate for the order of .
- The conclusion of step 17 can be proved using elementary group theory: since , the order of divides . If no proper divisor
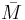 of realizes
of realizes 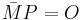 , then is the order of .
, then is the order of .
One drawback of this method is that there is a need for too much memory when the group becomes large. In order to address this, it might be more efficient to store only the coordinates of the points (along with the corresponding integer 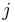 ). However, this leads to an extra scalar multiplication in order to choose between
). However, this leads to an extra scalar multiplication in order to choose between 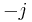 and
and 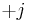 .
.
There are other generic algorithms for computing the order of a group element that are more space efficient, such as Pollard's rho algorithm and the Pollard kangaroo method. The Pollard kangaroo method allows one to search for a solution in a prescribed interval, yielding a running time of ![O(\sqrt[4]{q})](/2012-wikipedia_en_all_nopic_01_2012/I/b730894ea340ea18f377224feb883190.png) , using
, using 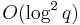 space.
space.
Schoof's algorithm
A theoretical breakthrough for the problem of computing the cardinality of groups of the type was achieved by René Schoof, who, in 1985, published the first deterministic polynomial time algorithm. Central to Schoof's algorithm are the use of division polynomials and Hasse's theorem, along with the Chinese remainder theorem.
Schoof's insight exploits the fact that, by Hasse's Theorem, there is a finite range of possible values for . It suffices to compute modulo an integer 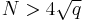 . This is achieved by computing modulo primes
. This is achieved by computing modulo primes  whose product exceeds , and then applying the Chinese remainder theorem. The key to the algorithm is using the division polynomial
whose product exceeds , and then applying the Chinese remainder theorem. The key to the algorithm is using the division polynomial 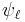 to efficiently compute modulo
to efficiently compute modulo 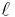 .
.
The running time of Schoof's Algorithm is polynomial in 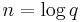 , with an asymptotic complexity of
, with an asymptotic complexity of 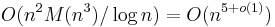 , where
, where 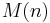 denotes the complexity of multiplication. Its space complexity is
denotes the complexity of multiplication. Its space complexity is 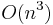 .
.
Schoof–Elkies–Atkin algorithm
In the 1990s, Noam Elkies, followed by A. O. L. Atkin devised improvements to Schoof's basic algorithm by making a distinction among the primes that are used. A prime is called an Elkies prime if the characteristic equation of the Frobenius endomorphism, 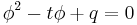 , splits over
, splits over 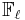 . Otherwise is called an Atkin prime. Elkies primes are the key to improving the asymptotic complexity of Schoof's algorithm. Information obtained from the Atkin primes permits a further improvement which is asymptotically negligible but can be quite important in practice. The modification of Schoof's algorithm to use Elkies and Atkin primes is known as the Schoof–Elkies–Atkin (SEA) algorithm.
. Otherwise is called an Atkin prime. Elkies primes are the key to improving the asymptotic complexity of Schoof's algorithm. Information obtained from the Atkin primes permits a further improvement which is asymptotically negligible but can be quite important in practice. The modification of Schoof's algorithm to use Elkies and Atkin primes is known as the Schoof–Elkies–Atkin (SEA) algorithm.
The status of a particular prime depends on the elliptic curve 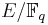 , and can be determined using the modular polynomial
, and can be determined using the modular polynomial 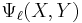 . If the univariate polynomial
. If the univariate polynomial 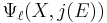 has a root in , where
has a root in , where 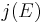 denotes the j-invariant of , then is an Elkies prime, and otherwise it is an Atkin prime. In the Elkies case, further computations involving modular polynomials are used to obtain a proper factor of the division polynomial
denotes the j-invariant of , then is an Elkies prime, and otherwise it is an Atkin prime. In the Elkies case, further computations involving modular polynomials are used to obtain a proper factor of the division polynomial 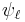 . The degree of this factor is
. The degree of this factor is 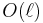 , whereas has degree
, whereas has degree 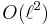 .
.
Unlike Schoof's algorithm, the SEA algorithm is typically implemented as a probabilistic algorithm (of the Las Vegas type), so that root-finding and other operations can be performed more efficiently. Its computational complexity is dominated by the cost of computing the modular polynomials , but as these do not depend on , they may be computed once and reused. Under the heuristic assumption that there are sufficiently many small Elkies primes, and excluding the cost of computing modular polynomials, the asymptotic running time of the SEA algorithm is 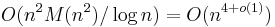 , where . Its space complexity is
, where . Its space complexity is 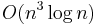 , but when precomputed modular polynomials are used this increases to
, but when precomputed modular polynomials are used this increases to 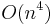 .
.
See also
- Schoof's algorithm
- Elliptic curve cryptography
- Baby-step giant-step
- Public key cryptography
- Schoof–Elkies–Atkin algorithm
- Pollard rho
- Pollard kangaroo
- Elliptic curve primality proving
Bibliography
- I. Blake, G. Seroussi, and N. Smart: Elliptic Curves in Cryptography, Cambridge University Press, 1999.
- A. Enge: Elliptic Curves and their Applications to Cryptography: An Introduction. Kluwer Academic Publishers, Dordrecht, 1999.
- G. Musiker: Schoof's Algorithm for Counting Points on . Available at http://www.math.umn.edu/~musiker/schoof.pdf
- R. Schoof: Counting Points on Elliptic Curves over Finite Fields. J. Theor. Nombres Bordeaux 7:219-254, 1995. Available at http://www.mat.uniroma2.it/~schoof/ctg.pdf
- L. C. Washington: Elliptic Curves: Number Theory and Cryptography. Chapman \& Hall/CRC, New York, 2003.
- C. Peters: Counting points on elliptic curves over . Available at http://www2.mat.dtu.dk/people/C.Peters/talks/2008.eccs.pdf